
大家可能都知道現在紅遍全世界的ChatGPT。但ChatGPT具體就竟是甚麼樣的技術?在這邊跟大家簡單科普一下~ (想要直接玩玩chatbot的人可以直接跳到Chatbase的部分XD)
他是一個藉由GPT-3(現在已經是GPT-4了)實現的聊天機器人。GPT-3(即Generative Pre-trained Transformer 3)是由OpenAI開發的一款自然語言處理(NLP)AI模型。其基本原理包括以下幾個方面:
- Transformer架構:GPT-3建立在Transformer架構之上,這是一種專為處理序列數據(例如文本)而設計的深度學習模型。Transformer使用自注意力機制來捕捉序列中的上下文相關信息,這使得模型能夠有效地學習長範圍的依賴關係。
- 大規模語料庫預訓練:GPT-3通過在大量文本數據上進行無監督的預訓練,學習語言的統計規律和知識。這些文本數據來自於網絡上的各種資源,例如維基百科、書籍、新聞等。預訓練的目標是讓模型學會生成與訓練數據相似的文本。
- 微調(Fine-tuning):在預訓練後,GPT-3可以通過有監督學習對特定任務進行微調。這需要標記過的訓練數據,其中包括用戶輸入和期望的模型回應。微調使得模型能夠適應特定的應用場景,例如問答、情感分析或文本摘要等。
- 自回歸語言模型:GPT-3是一個自回歸語言模型,這意味著它通過預測序列中下一個單詞(或代碼)來生成文本。在生成過程中,模型會根據已經生成的單詞和輸入的文本,為下一個單詞生成概率分布,然後從這個分布中選擇最可能的單詞(或使用一些隨機性生成更有趣的結果)。
總之,GPT-3的原理基於Transformer架構,通過大規模預訓練和微調過程來學習語言知識。這使得它能夠理解輸入文本的上下文並生成相關的回應。
其中OpenAI有開放微調(Fine-tuning)功能,這使得訓練專屬聊天機器人變成有可能的事情!
Fine-tuning(微調)
那Fine-tuning到底是甚麼呢? Fine-tuning(微調)是深度學習中的一個常用技術,通常用於將預先訓練好的神經網絡模型適應特定的應用場景。微調的過程包括以下步驟:
- 預訓練模型:在大量的數據集(例如文本、圖像等)上進行無監督或有監督的訓練,使模型學會基本的特徵和表示。這個過程中,模型會學到很多通用的知識,例如在自然語言處理中學習語法、詞彙和一些常見的語境。
- 特定任務的訓練數據:為了將預訓練模型應用到特定的任務(例如情感分析、文本摘要等),需要準備一個相關的標記過的數據集。這個數據集包含了用戶輸入以及對應的正確回應或標籤,模型需要根據這些數據進行學習。
- 微調過程:將預訓練模型的權重作為初始值,然後在特定任務的訓練數據上進行有監督學習。通常,微調的學習率要比預訓練時的學習率低,以保留已經學到的通用知識,同時讓模型能夠根據新的數據集進行適應。
- 評估和應用:在微調完成後,可以使用驗證數據集來評估模型在特定任務上的性能。如果性能達到了滿意的水平,則可以將微調後的模型應用到實際場景中。
以我們要來討論的案例來說,fine-tuning(微調)就是讓聰明的chatGPT去學習特定知識。例如爐石戰記的相關知識與新聞,這樣他就能夠成為專屬的爐石戰記聊天助理!
OpenAI 提供API讓用戶可以直接呼叫chatGPT,並提供了fine-tune API去依照自己的需求調整chatGPT。需要注意的是目前fine-tune使用的GPT版本是gpt3,而不是現在線上的chatGPT (gpt3.5-turbo),效果上略有差距。
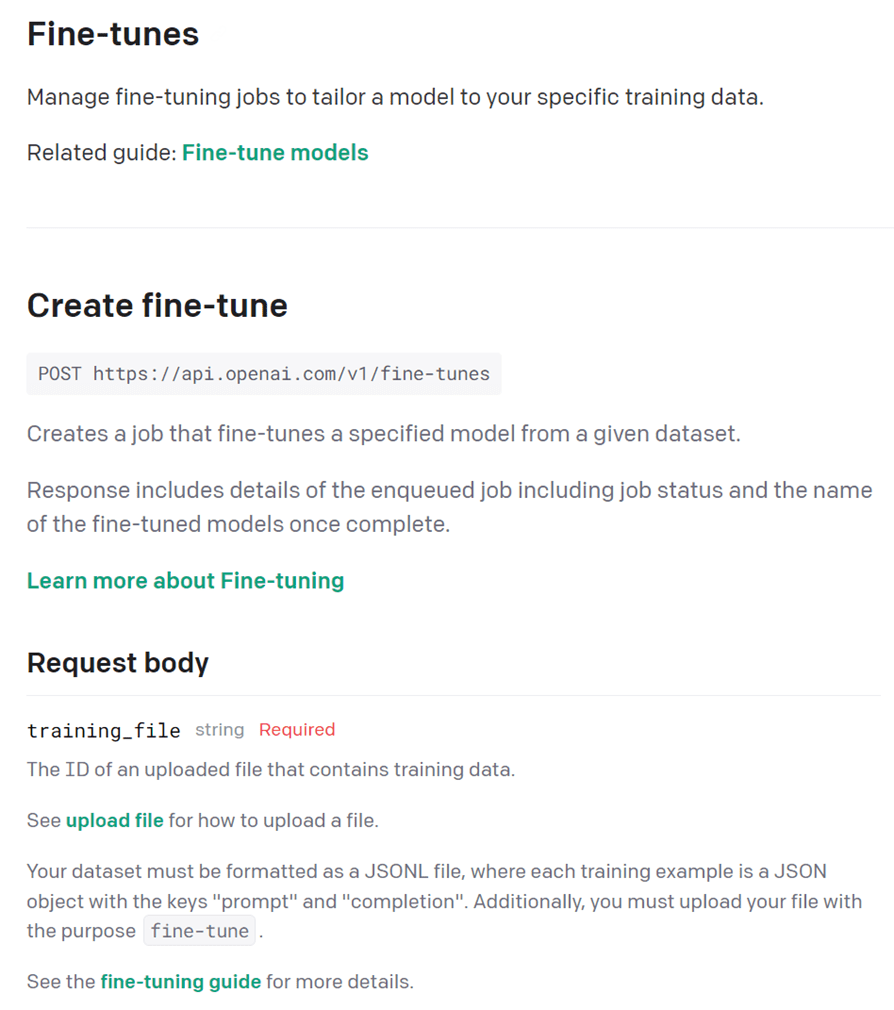
首先要先OpenAI的CLI
安裝python3.10(不能用太舊版的!) >> pip install openai
接著準備訓練資料,使用jsonl的資料格式,範例如下:
{“prompt": “", “completion": “"}
{“prompt": “", “completion": “"}
{“prompt": “", “completion": “"}
…
prompt就是用戶問的問題,completion就是你希望AI回答的標準答案
整理訓練資料應該是最費工的部分了。
準備好資料就可以呼叫API來進行訓練~
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <MODEL>
此外藉由調整訓練超參數可以讓chatGPT更有效的擬合到你輸入的客製化資料
model:需要進行微調的基礎模型的名稱。你可以選擇 “ada"、"babbage" 、"curie" 或 “davinci" 中的一種。欲了解更多關於這些模型的資訊,可以參考OpenAI的模型(Models)文檔。
n_epochs:默認為4。訓練模型的迭代次數(epochs)。一個迭代次數指的是對訓練數據集進行一次完整的遍歷。
batch_size:默認為訓練集樣本數量的約0.2%,上限為256。批量大小(batch size)是用於執行一次前向和後向傳播訓練的訓練樣本數。對於較大的數據集,較大的批量大小往往效果更好。
learning_rate_multiplier:根據最終的batch_size,默認為0.05,0.1或0.2。微調學習率(fine-tuning learning rate)是預訓練用的原始學習率乘以此倍數。OpenAI建議在0.02到0.2的範圍內調整。
實際訓練情況因為是公司內部業務所以就沒辦法跟大家分享了,但以下的Chatbase進一步提供更簡單的方式讓你可以自己輕鬆玩chatGPT!在這邊附上一個簡單範例哈哈
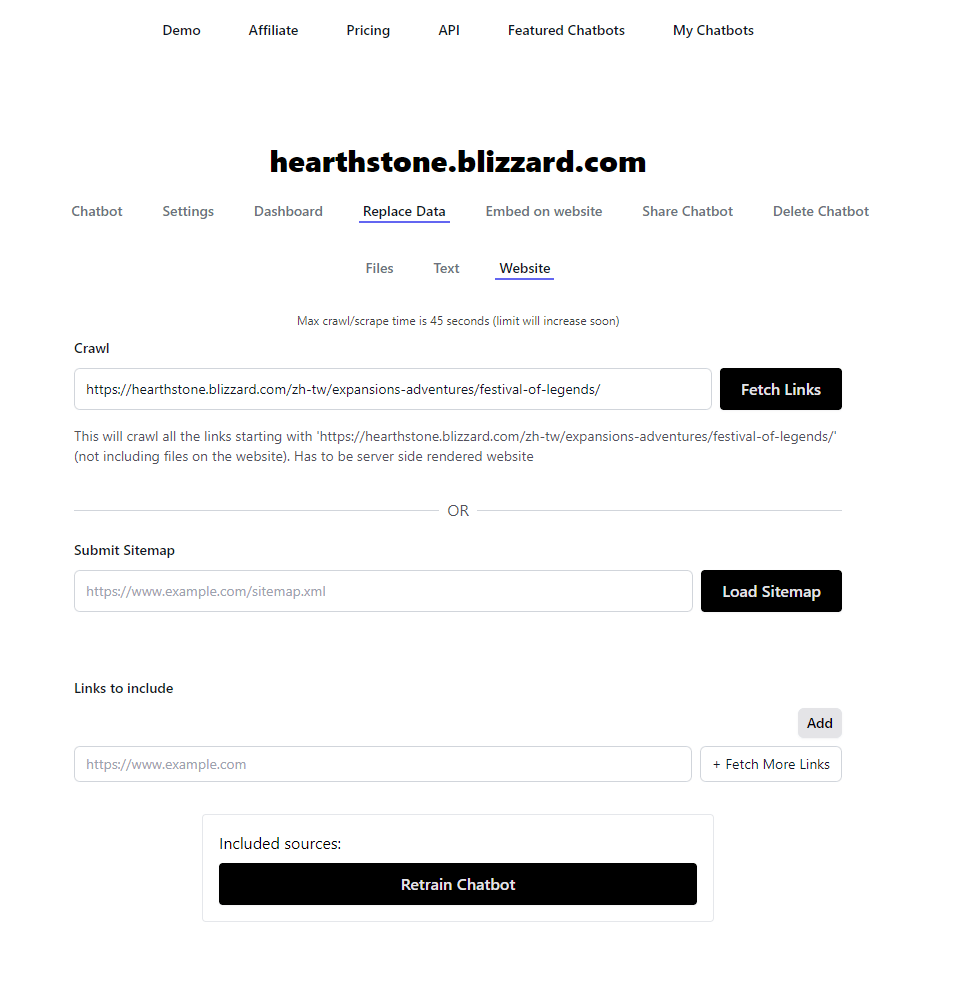
這個網站提供UI介面讓不會寫程式的人也可以簡單訓練chatGPT。只要簡單將資料上傳,或甚至輸入特定網址就可以訓練聊天機器人了,此外他提供的居然是最新的gpt3.5-turbo和gpt4,訓練效果還不錯!目前如果不做任何調整直接使用OpenAI自家的fine-tune和Chatbase的fine-tune,竟然是Chatbase略勝一籌!當然OpenAI的使用彈性和上限更高些。靜待未來的變化哈哈。
Chatbase只要像這樣上傳圖片或者貼上網址即可訓練
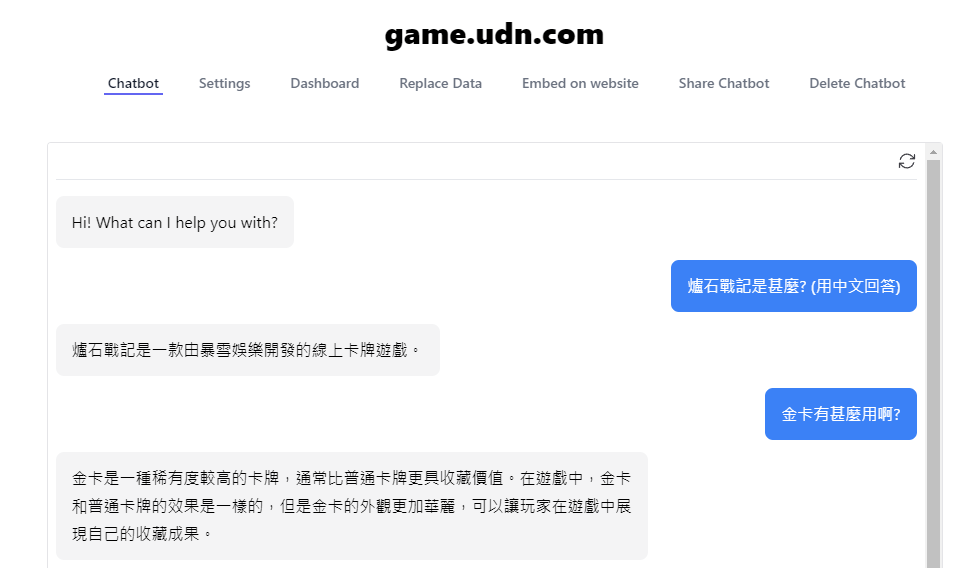
訓練出來的聊天機器人就像這樣 (祝大家玩得愉快XD)~

發表留言